
根據 AMD 最新發表的一篇研究論文,該公司正探索在未來處理器中導入「堆疊式 L2 快取」的可能性,其延遲表現可達到與傳統平面式設計相同,甚至更低的水準。

AMD 近日公開一篇名為《Balanced Latency Stacked Cache》的研究文件,並已提交專利申請(專利號:US20260003794A1)。論文中揭露了一種「延遲平衡的堆疊式快取」設計概念,其堆疊快取系統包含第一顆快取晶粒,以及至少一顆以上、以垂直方式堆疊的第二快取晶粒。
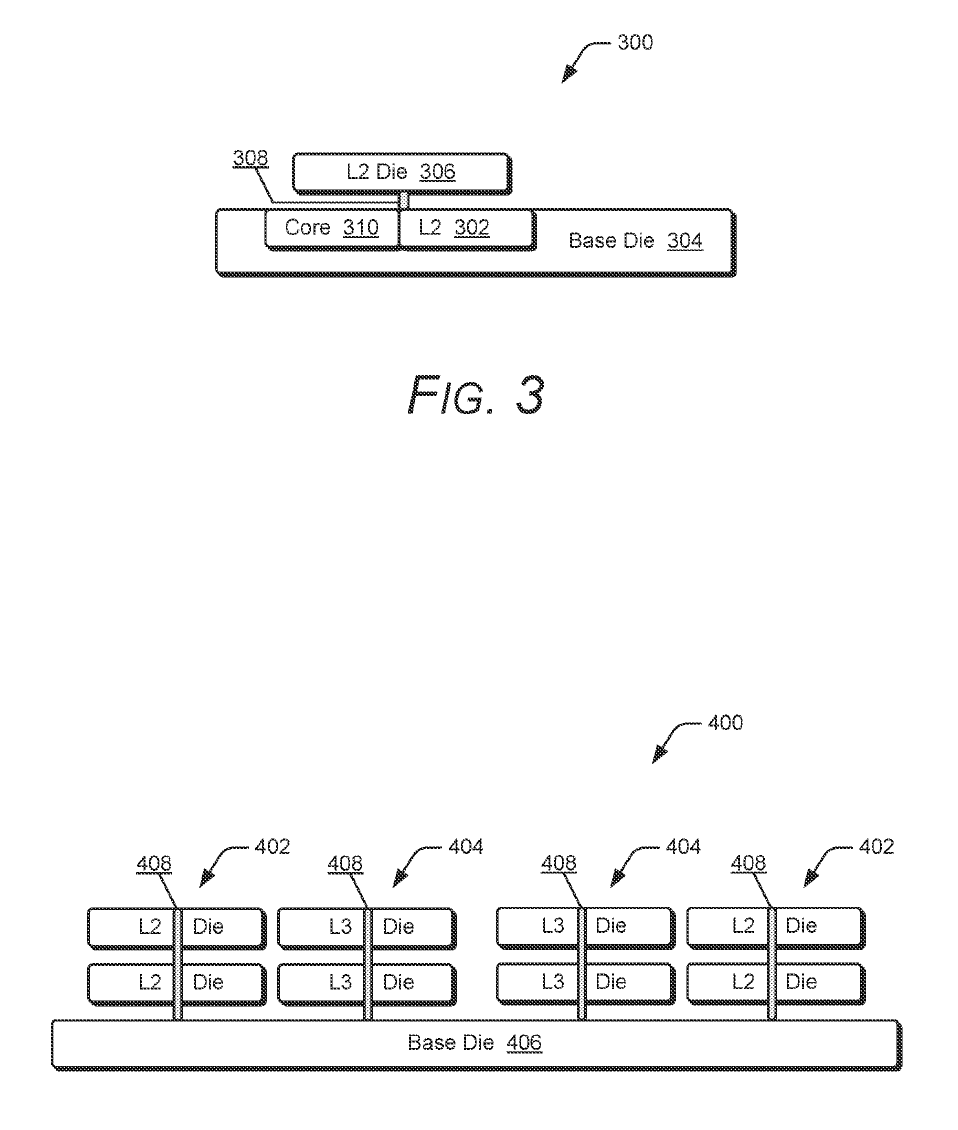
目前 AMD 已在產品中廣泛採用 3D V-Cache 技術,透過額外堆疊一層 L3 快取,提升處理器效能。第一代 3D V-Cache 將快取堆疊於 Zen 計算晶粒之上,而第二代則改為堆疊於計算晶粒下方;兩者本質上都是利用垂直堆疊的快取架構。
這項技術已從消費級的 Ryzen 系列,一路延伸至資料中心等級的 EPYC 處理器。如今,AMD 在持續發展 L3 3D V-Cache 的同時,也開始探索將「L2 快取堆疊化」的可能性,專利內容顯示,L2 快取堆疊將是下一步研究方向。
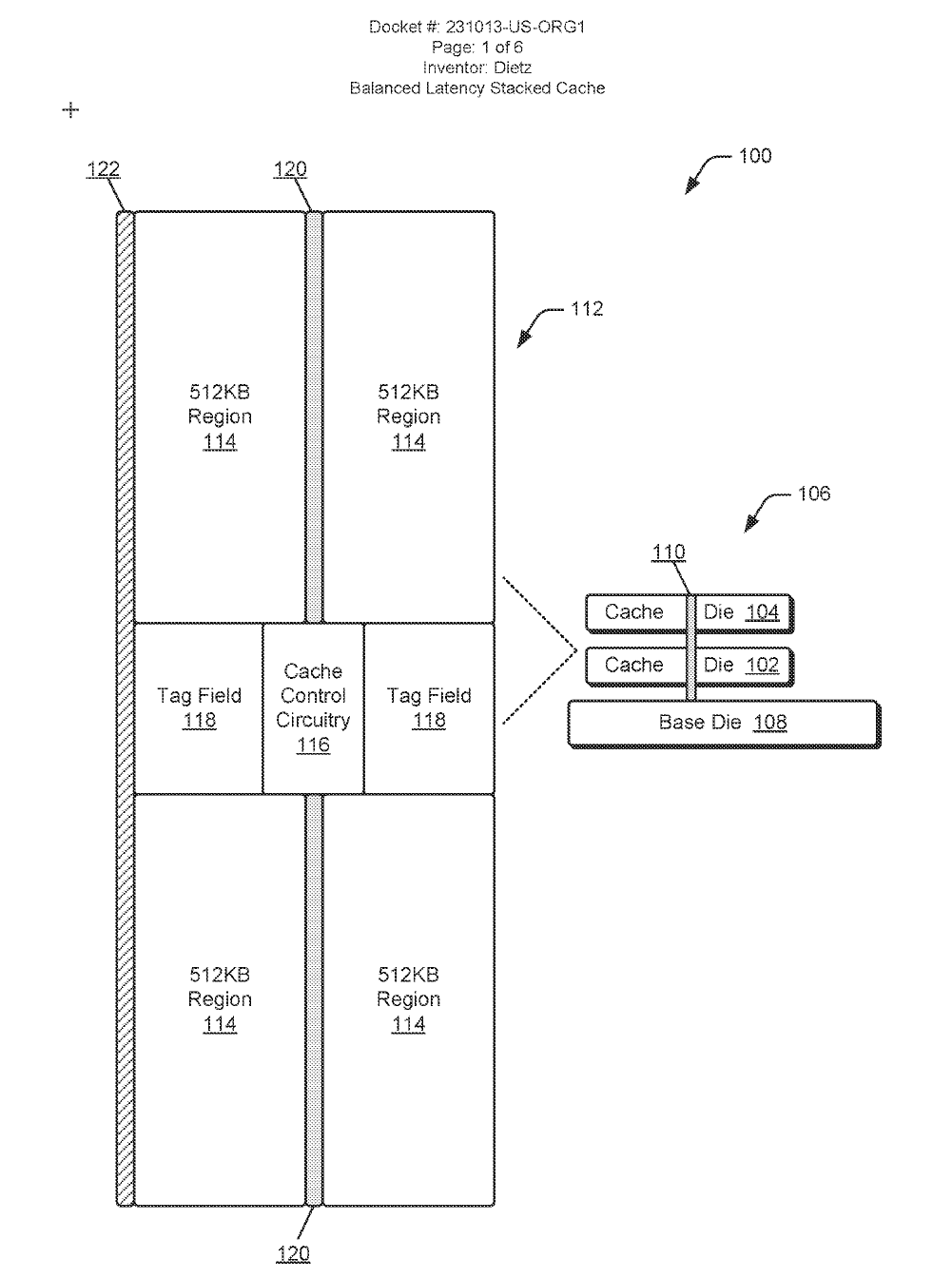
此堆疊方式延續 3D V-Cache 的核心概念,透過矽穿孔(Silicon Vias)將 L2/L3 快取堆疊與基礎晶粒及計算單元垂直連接,矽穿孔配置於堆疊快取系統的中央位置,由 CCC 負責控制資料的輸入與輸出。
這代表堆疊式 L2 快取不僅能提供更高的容量,甚至在延遲表現上,也可達到與平面式設計相同,或更佳的水準。
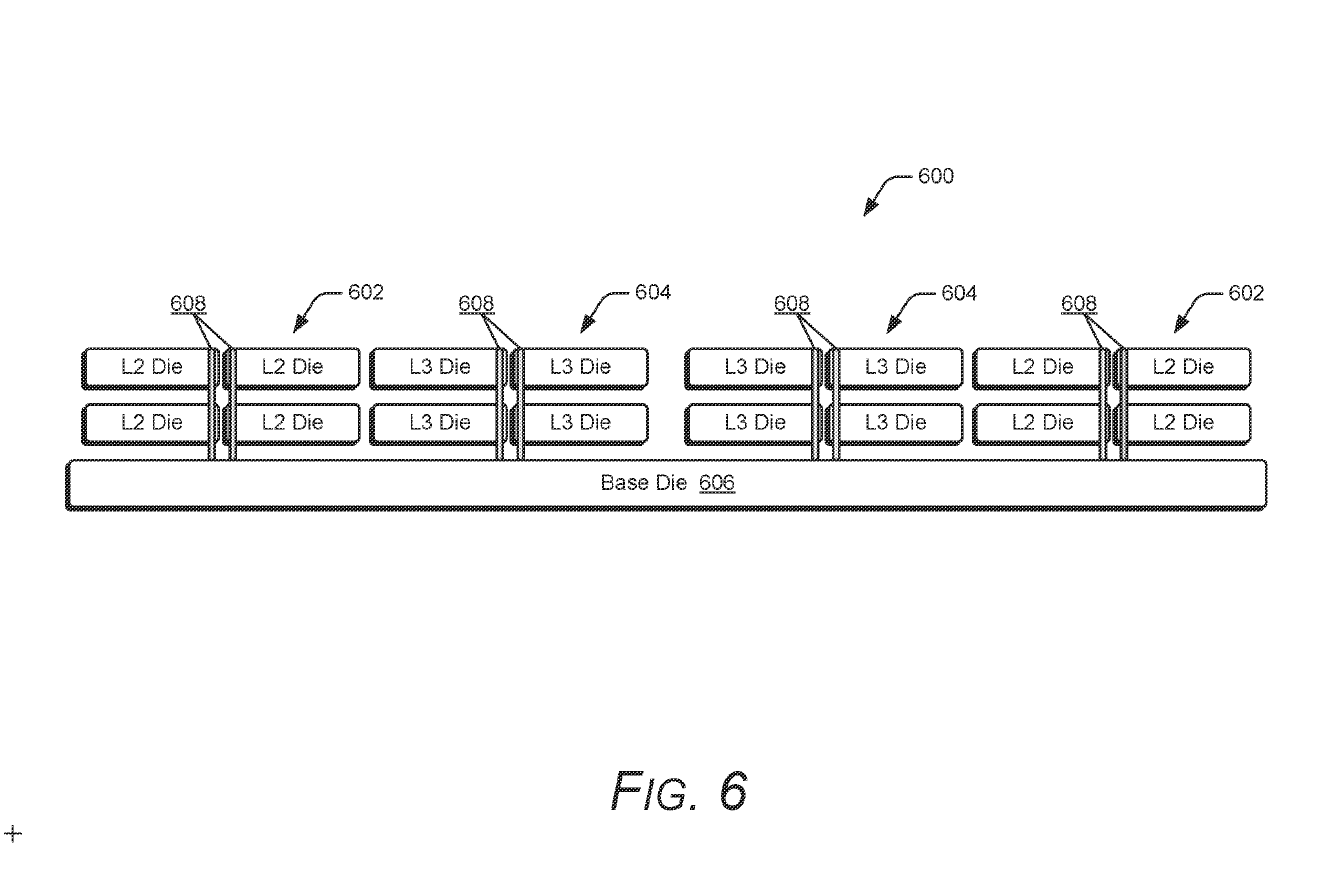
由於資料進出距離縮短,堆疊快取的兩側能達成延遲平衡(或相同延遲)。相較於平面式 1 MB L2M 快取的 14 個週期延遲,堆疊設計可降至 12 個週期,讓更大容量的快取仍能維持甚至優於傳統的延遲表現。
此外,由於存取週期縮短,快取單元啟用時間減少,也能更快從運作狀態切換至閒置狀態,進一步降低功耗。加上佈線更短、電容更低、訊號負載減少,整體發熱量也隨之下降。
來源
AMD 近日公開一篇名為《Balanced Latency Stacked Cache》的研究文件,並已提交專利申請(專利號:US20260003794A1)。論文中揭露了一種「延遲平衡的堆疊式快取」設計概念,其堆疊快取系統包含第一顆快取晶粒,以及至少一顆以上、以垂直方式堆疊的第二快取晶粒。
目前 AMD 已在產品中廣泛採用 3D V-Cache 技術,透過額外堆疊一層 L3 快取,提升處理器效能。第一代 3D V-Cache 將快取堆疊於 Zen 計算晶粒之上,而第二代則改為堆疊於計算晶粒下方;兩者本質上都是利用垂直堆疊的快取架構。
這項技術已從消費級的 Ryzen 系列,一路延伸至資料中心等級的 EPYC 處理器。如今,AMD 在持續發展 L3 3D V-Cache 的同時,也開始探索將「L2 快取堆疊化」的可能性,專利內容顯示,L2 快取堆疊將是下一步研究方向。
堆疊式 L2 快取設計細節
在專利示意中,AMD 描述了一種基礎晶粒(Base Die),其上連接計算晶粒與快取晶粒,再於其上進一步堆疊另一組計算與快取晶粒。該範例中的 L2 快取模組由四個 512 KB 區塊組成,合計 2 MB L2 快取,並搭配 CCC(Cache Control Circuitry,快取控制電路)。依照設計需求,該 L2 快取結構可擴充至最高 4 MB。
此堆疊方式延續 3D V-Cache 的核心概念,透過矽穿孔(Silicon Vias)將 L2/L3 快取堆疊與基礎晶粒及計算單元垂直連接,矽穿孔配置於堆疊快取系統的中央位置,由 CCC 負責控制資料的輸入與輸出。
延遲不升反降,甚至優於平面式設計
論文中以 1 MB 與 2 MB 的平面式 L2 快取作為比較基準。傳統平面式 1 MB L2M 快取的典型延遲約為 14 個時脈週期,而採用堆疊設計的 1 MB L2M 快取,延遲則可降低至 12 個時脈週期。這代表堆疊式 L2 快取不僅能提供更高的容量,甚至在延遲表現上,也可達到與平面式設計相同,或更佳的水準。
中央佈線設計,帶來延遲與功耗優勢
AMD 指出,透過將連接用的矽穿孔集中設置於堆疊快取系統的中央,可在存取堆疊快取時降低回應延遲,並同時達到節能效果。與傳統平面式快取需額外佈線(亦稱為管線階段)將資料從 I/O 傳送至較遠區域不同,該設計避免了額外的佈線階段。
由於資料進出距離縮短,堆疊快取的兩側能達成延遲平衡(或相同延遲)。相較於平面式 1 MB L2M 快取的 14 個週期延遲,堆疊設計可降至 12 個週期,讓更大容量的快取仍能維持甚至優於傳統的延遲表現。
此外,由於存取週期縮短,快取單元啟用時間減少,也能更快從運作狀態切換至閒置狀態,進一步降低功耗。加上佈線更短、電容更低、訊號負載減少,整體發熱量也隨之下降。
未來是否導入產品,仍待觀察
除了延遲優勢,AMD 也在論文中明確指出,堆疊式 L2 快取可帶來顯著的功耗節省。不過,距離實際在晶片上看到這類設計,可能還需要一段時間。來源