
Google 最近一項名為 TurboQuant 的新型量化技術近日公開,主打在不影響模型準確度的前提下,大幅降低大型語言模型(LLM)與向量搜尋系統的記憶體需求,並改善長期存在的效能瓶頸問題。是好消息,但對記憶體廠可能不是...聽聞後股票大跌...

隨著 AI 模型規模不斷擴大,高維度向量已成為理解語意與資料特徵的核心結構,但其龐大的記憶體消耗,也讓關鍵的 KV Cache(鍵值快取)成為系統效能的限制之一。傳統的向量量化技術雖能壓縮資料,但往往需要額外儲存量化參數,反而產生新的記憶體負擔。
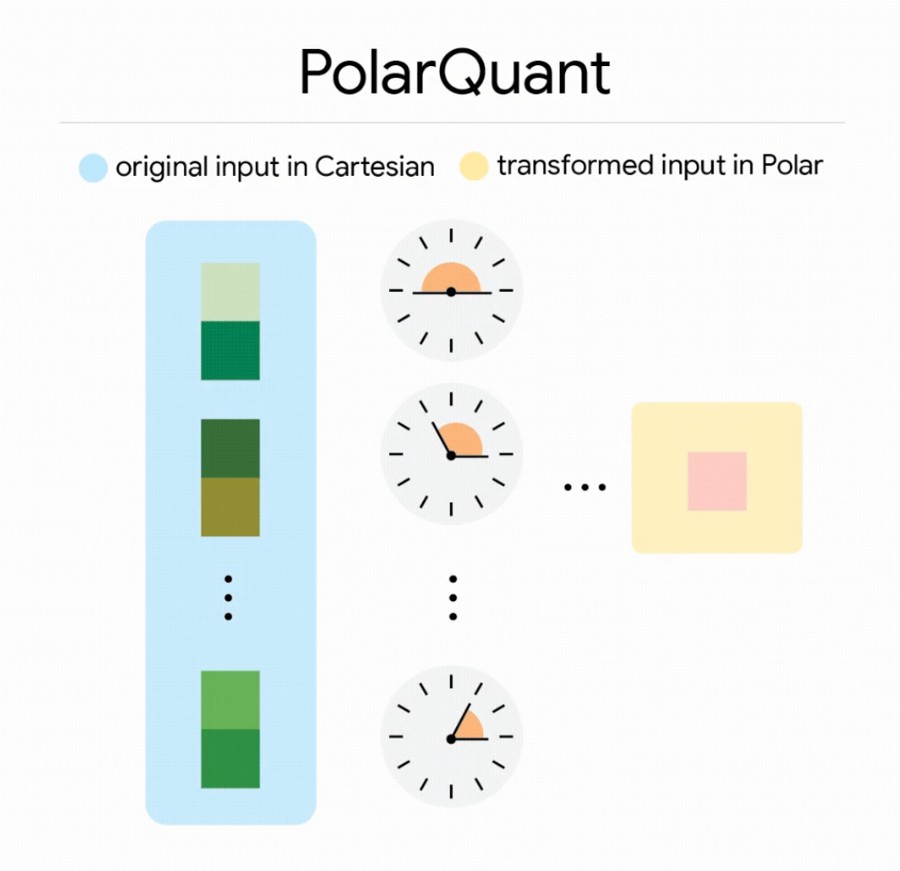
TurboQuant 嘗試解決這一問題。該方法結合兩種新演算法——PolarQuant 與 Quantized Johnson-Lindenstrauss——在壓縮效率與精準度之間取得平衡。整體設計分為兩個階段:首先透過資料旋轉與高品質量化保留主要資訊,再利用極低位元(僅 1 bit)處理殘餘誤差,降低偏差並維持計算準確性。
其中,QJL 利用 Johnson-Lindenstrauss Transform 將高維資料壓縮為僅包含符號資訊的形式,在幾乎不增加記憶體負擔的情況下保留資料間距離關係;而 PolarQuant 則改以極座標方式重新表達向量,藉由固定結構減少傳統方法所需的額外運算與儲存成本。
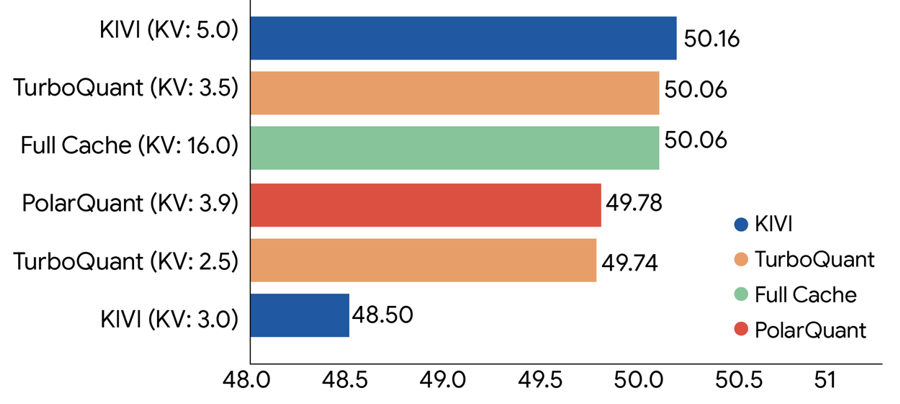
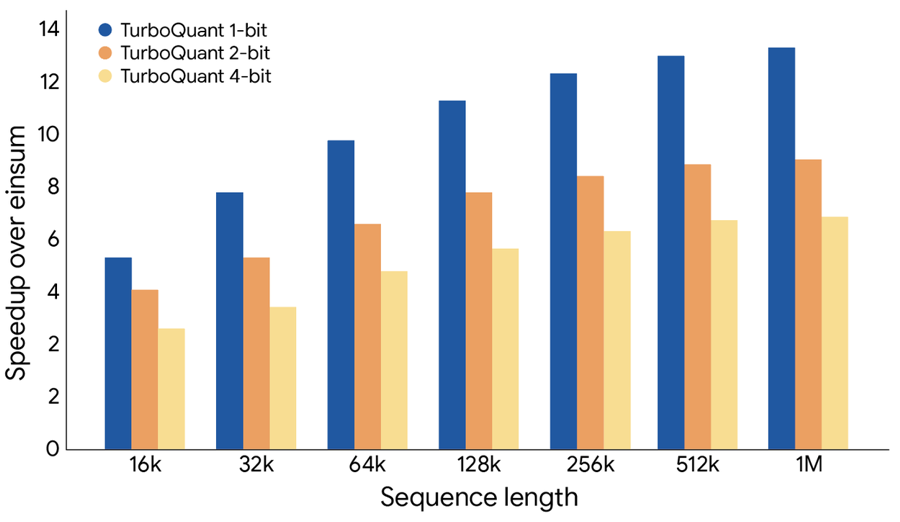
在多項長文本與搜尋任務測試中(包括 LongBench、ZeroSCROLLS 等基準),TurboQuant 展現出接近無損的壓縮效果。實驗顯示,其可將 KV Cache 記憶體占用降低至少 6 倍,同時維持模型輸出品質。此外,在 H100 GPU 平台上,4-bit 設定相較未壓縮的 32-bit 計算,最高可帶來約 8 倍的注意力計算加速。
除了語言模型外,該技術在高維向量搜尋領域同樣展現優勢。在與現有方法比較時,TurboQuant 在 recall 表現上持續優於傳統方案,即使後者使用更複雜的資料結構與調校流程。
研究團隊指出,這類壓縮技術不僅有助於解決大型模型的記憶體瓶頸,也將對語意搜尋(semantic search)帶來實質影響。隨著搜尋技術從關鍵字比對轉向語意理解,向量搜尋需求快速成長,如何在有限資源下處理海量向量資料,已成為關鍵挑戰。
整體而言,TurboQuant 被視為一種兼具理論基礎與實務價值的演算法進展,未來在 AI 模型部署與大規模搜尋系統中的應用潛力,仍有待進一步觀察。
隨著 AI 模型規模不斷擴大,高維度向量已成為理解語意與資料特徵的核心結構,但其龐大的記憶體消耗,也讓關鍵的 KV Cache(鍵值快取)成為系統效能的限制之一。傳統的向量量化技術雖能壓縮資料,但往往需要額外儲存量化參數,反而產生新的記憶體負擔。
TurboQuant 嘗試解決這一問題。該方法結合兩種新演算法——PolarQuant 與 Quantized Johnson-Lindenstrauss——在壓縮效率與精準度之間取得平衡。整體設計分為兩個階段:首先透過資料旋轉與高品質量化保留主要資訊,再利用極低位元(僅 1 bit)處理殘餘誤差,降低偏差並維持計算準確性。
其中,QJL 利用 Johnson-Lindenstrauss Transform 將高維資料壓縮為僅包含符號資訊的形式,在幾乎不增加記憶體負擔的情況下保留資料間距離關係;而 PolarQuant 則改以極座標方式重新表達向量,藉由固定結構減少傳統方法所需的額外運算與儲存成本。
在多項長文本與搜尋任務測試中(包括 LongBench、ZeroSCROLLS 等基準),TurboQuant 展現出接近無損的壓縮效果。實驗顯示,其可將 KV Cache 記憶體占用降低至少 6 倍,同時維持模型輸出品質。此外,在 H100 GPU 平台上,4-bit 設定相較未壓縮的 32-bit 計算,最高可帶來約 8 倍的注意力計算加速。
除了語言模型外,該技術在高維向量搜尋領域同樣展現優勢。在與現有方法比較時,TurboQuant 在 recall 表現上持續優於傳統方案,即使後者使用更複雜的資料結構與調校流程。
研究團隊指出,這類壓縮技術不僅有助於解決大型模型的記憶體瓶頸,也將對語意搜尋(semantic search)帶來實質影響。隨著搜尋技術從關鍵字比對轉向語意理解,向量搜尋需求快速成長,如何在有限資源下處理海量向量資料,已成為關鍵挑戰。
整體而言,TurboQuant 被視為一種兼具理論基礎與實務價值的演算法進展,未來在 AI 模型部署與大規模搜尋系統中的應用潛力,仍有待進一步觀察。