傳聞指出,NVIDIA 下一代代號 Feynman 的 GPU 架構,可能會在 2028 年前後導入來自 Groq 的 LPU(Language Processing Unit)單元,目標是進一步強化推論(Inference)效能,並在 AI 運算市場持續擴大領先優勢。

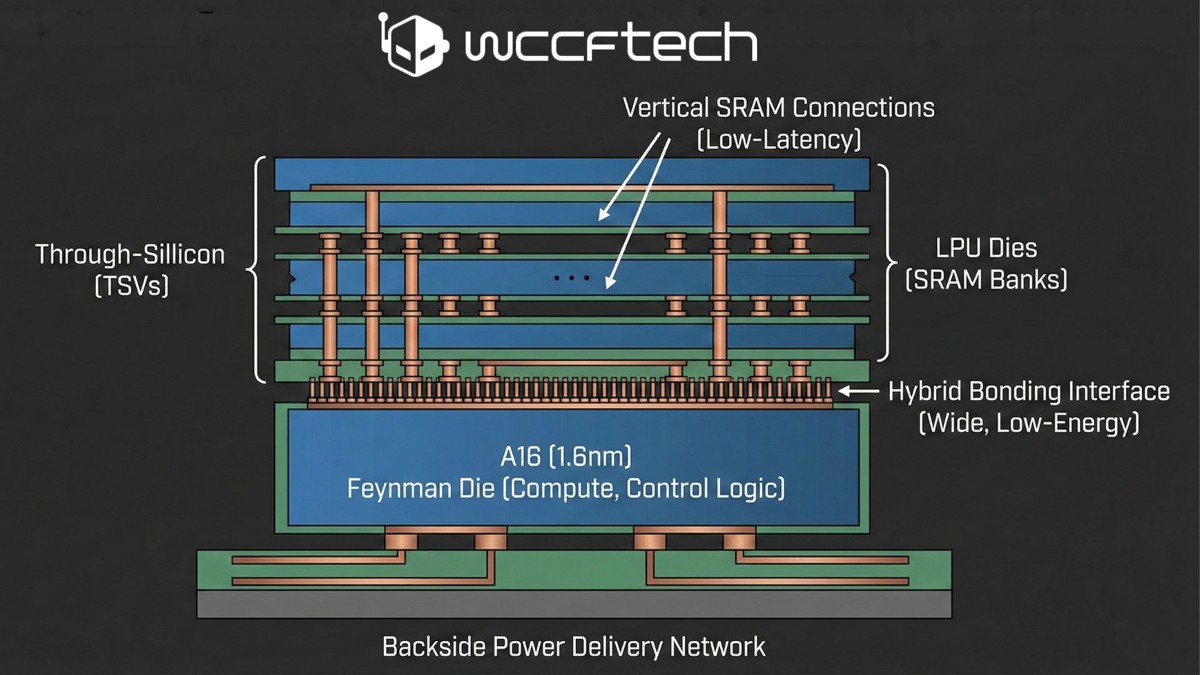
根據 GPU 架構領域專家 AGF 的看法,NVIDIA 很可能不會將 LPU 直接做成單一大型晶片,而是採取類似 AMD X3D 處理器的做法,透過 TSMC 的 SoIC 混合鍵合(Hybrid Bonding)技術,將 LPU 以「堆疊晶粒」的方式整合到 Feynman GPU 上。
AGF 認為,若將大量 SRAM 直接建構在先進製程上,效益其實不高。一方面 SRAM 在製程微縮上的收益有限,另一方面,使用高階製程來生產大量記憶體,也會大幅拉高單位晶圓成本,反而不划算。因此,較合理的做法,是將運算核心與控制邏輯集中在主 GPU 晶粒,而把包含大量 SRAM 的 LPU 做成獨立晶粒,再進行 3D 堆疊。
圖片來源 Wccftech
在這樣的設計下,Feynman GPU 的主晶片可能會採用像是 A16(1.6nm) 等先進製程,負責張量運算、控制邏輯等高密度運算單元;而 LPU 晶粒則專注於提供大容量、低延遲的 SRAM。兩者之間透過混合鍵合技術連接,不僅能提供比封裝外記憶體更寬的介面,也能降低每 bit 的能耗。
此外,A16 製程預期將導入背面供電(Backside Power Delivery),使晶片正面能騰出空間,專門用於垂直 SRAM 連接,有助於降低延遲,對推論這類重視即時反應的工作負載特別有利。
不過,這種堆疊式設計也並非沒有風險。首先是散熱問題,高密度運算晶片本身就已經面臨熱設計挑戰,再加上主打長時間穩定吞吐的 LPU,如何避免熱點與效能瓶頸,將是一大考驗。其次,在執行層面,LPU 偏向固定執行順序與高度確定性的設計,與 GPU 原本強調彈性與平行調度的特性,可能產生衝突。
更大的挑戰,其實來自軟體層。CUDA 的設計理念是盡量抽象化硬體細節,而 LPU 架構則往往需要更明確的記憶體配置與資料流控制。如何讓 CUDA 在 LPU + GPU 的混合環境下順利運作,並發揮效能,將對 NVIDIA 的軟硬體整合能力提出極高要求。
即便如此,若 NVIDIA 真能成功解決這些問題,導入 LPU 的 Feynman GPU 有望在推論領域建立新的技術門檻。對於志在全面主導 AI 運算堆疊的 NVIDIA 而言,這或許正是它願意付出的代價。
根據 GPU 架構領域專家 AGF 的看法,NVIDIA 很可能不會將 LPU 直接做成單一大型晶片,而是採取類似 AMD X3D 處理器的做法,透過 TSMC 的 SoIC 混合鍵合(Hybrid Bonding)技術,將 LPU 以「堆疊晶粒」的方式整合到 Feynman GPU 上。
AGF 認為,若將大量 SRAM 直接建構在先進製程上,效益其實不高。一方面 SRAM 在製程微縮上的收益有限,另一方面,使用高階製程來生產大量記憶體,也會大幅拉高單位晶圓成本,反而不划算。因此,較合理的做法,是將運算核心與控制邏輯集中在主 GPU 晶粒,而把包含大量 SRAM 的 LPU 做成獨立晶粒,再進行 3D 堆疊。
圖片來源 Wccftech
在這樣的設計下,Feynman GPU 的主晶片可能會採用像是 A16(1.6nm) 等先進製程,負責張量運算、控制邏輯等高密度運算單元;而 LPU 晶粒則專注於提供大容量、低延遲的 SRAM。兩者之間透過混合鍵合技術連接,不僅能提供比封裝外記憶體更寬的介面,也能降低每 bit 的能耗。
此外,A16 製程預期將導入背面供電(Backside Power Delivery),使晶片正面能騰出空間,專門用於垂直 SRAM 連接,有助於降低延遲,對推論這類重視即時反應的工作負載特別有利。
不過,這種堆疊式設計也並非沒有風險。首先是散熱問題,高密度運算晶片本身就已經面臨熱設計挑戰,再加上主打長時間穩定吞吐的 LPU,如何避免熱點與效能瓶頸,將是一大考驗。其次,在執行層面,LPU 偏向固定執行順序與高度確定性的設計,與 GPU 原本強調彈性與平行調度的特性,可能產生衝突。
更大的挑戰,其實來自軟體層。CUDA 的設計理念是盡量抽象化硬體細節,而 LPU 架構則往往需要更明確的記憶體配置與資料流控制。如何讓 CUDA 在 LPU + GPU 的混合環境下順利運作,並發揮效能,將對 NVIDIA 的軟硬體整合能力提出極高要求。
即便如此,若 NVIDIA 真能成功解決這些問題,導入 LPU 的 Feynman GPU 有望在推論領域建立新的技術門檻。對於志在全面主導 AI 運算堆疊的 NVIDIA 而言,這或許正是它願意付出的代價。