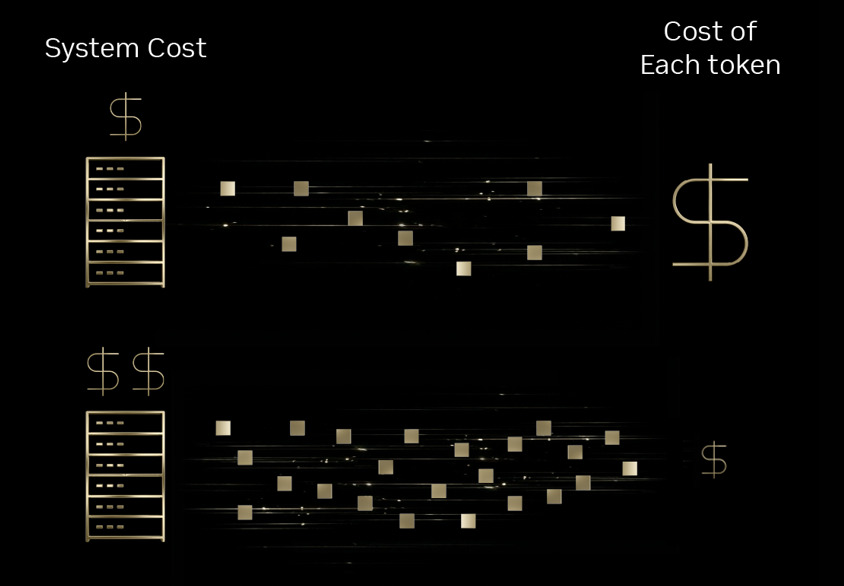
NVIDIA 近期在官方部落格中表示,新一代 Blackwell 架構在 AI 推論(inference)效率方面取得顯著進展,尤其是在每個 token 成本(tokenomics)上,相較前代 Hopper 平台可降低最高達 10 倍。這項成果被歸因於 NVIDIA 所稱的極致軟硬體協同設計(extreme co-design)策略。

隨著多家業者陸續部署 Blackwell 平台,包括 Baseten、DeepInfra、Fireworks AI 與 Together AI 等推論服務供應商已導入相關系統,用於託管大型開源模型。NVIDIA 指出,這些業者在相同推論負載下,能將每 token 成本壓低至 Hopper 世代的十分之一,同時維持低延遲與穩定輸出。
Blackwell 架構的一大核心在於針對當前主流的 MoE(Mixture of Experts)模型進行最佳化。以 GB200 NVL72 系統為例,其採用 72 顆晶片組成的大規模配置,並搭配約 30TB 的高速共享記憶體,強化專家模型並行處理能力。透過更精細的 token 批次切分與跨 GPU 分配機制,系統可在大規模推論場景下提高資源利用率,進而降低整體運算成本。
NVIDIA 表示,Blackwell 在硬體與軟體層面的整合優化,是推動效率提升的關鍵。除了硬體架構本身的改進,也包括對推論堆疊(inference stack)與通訊機制的深度調校。部分業者指出,在多代理(multi-agent)與專用 AI 代理應用場景下,成本效率可較 Hopper 世代改善 25% 至 50%。
展望後續產品,NVIDIA 已預告下一代平台 Vera Rubin 將進一步強化基礎設施效率,包含新架構設計與專用機制(例如針對預填階段優化的技術)等。隨著 AI 模型規模與推論需求快速擴張,業界普遍認為,提升硬體效率與降低單位運算成本,將成為未來競爭的關鍵指標之一。
隨著多家業者陸續部署 Blackwell 平台,包括 Baseten、DeepInfra、Fireworks AI 與 Together AI 等推論服務供應商已導入相關系統,用於託管大型開源模型。NVIDIA 指出,這些業者在相同推論負載下,能將每 token 成本壓低至 Hopper 世代的十分之一,同時維持低延遲與穩定輸出。
Blackwell 架構的一大核心在於針對當前主流的 MoE(Mixture of Experts)模型進行最佳化。以 GB200 NVL72 系統為例,其採用 72 顆晶片組成的大規模配置,並搭配約 30TB 的高速共享記憶體,強化專家模型並行處理能力。透過更精細的 token 批次切分與跨 GPU 分配機制,系統可在大規模推論場景下提高資源利用率,進而降低整體運算成本。
NVIDIA 表示,Blackwell 在硬體與軟體層面的整合優化,是推動效率提升的關鍵。除了硬體架構本身的改進,也包括對推論堆疊(inference stack)與通訊機制的深度調校。部分業者指出,在多代理(multi-agent)與專用 AI 代理應用場景下,成本效率可較 Hopper 世代改善 25% 至 50%。
展望後續產品,NVIDIA 已預告下一代平台 Vera Rubin 將進一步強化基礎設施效率,包含新架構設計與專用機制(例如針對預填階段優化的技術)等。隨著 AI 模型規模與推論需求快速擴張,業界普遍認為,提升硬體效率與降低單位運算成本,將成為未來競爭的關鍵指標之一。