
在全新業界標準基準測試中,雲端服務供應商CoreWeave的一個由3,584個H100 GPU組成的集群僅用了11分鐘就訓練完成一個基於GPT-3的龐大模型
領先的使用者和業界標準基準測試一致同意:NVIDIA H100 Tensor Core GPUs提供了最佳的人工智慧效能,特別是在支援生成式人工智慧的大型語言模型(LLM)方面。

在今天發布的最新MLPerf訓練基準測試中,H100 GPU在所有八項測試中創下了新紀錄,在針對生成式人工智慧的新 MLPerf 測試中表現出色。這種卓越的性能能夠在大型伺服器上以單個加速器和多台GPU伺服器的方式展現。
舉例來說,專門從事 GPU 加速工作負載的雲端服務供應商 CoreWeave與新創公司 Inflection AI共同開發並由 CoreWeave負責營運的一個可商用的3,584個H100 GPU集群,此系統在不到11分鐘的時間內完成了大規模的GPT-3訓練基準測試。
CoreWeave聯合創辦人暨技術長Brian Venturo表示: 「由於我們在快速、低延遲 InfiniBand 網路上運行數千個 H100 GPU,我們的客戶如今能大規模地構建最先進的生成式人工智慧和大型語言模型。我們與NVIDIA一同提交的MLPerf成果清楚顯示了我們的客戶享受到的卓越效能。」
當今最高效能
Inflection AI利用這種效能為其第一個名為Pi的個人人工智慧打造先進大型語言模型,該公司將扮演一個人工智慧工作室,打造讓使用者可以透過簡單、自然方式與之互動的個人人工智慧。
Inflection AI 執行長 Mustafa Suleyman 表示:「如今,任何人都可以體驗基於我們最先進大型語言模型的個人人工智慧的強大功能,該模型是在 CoreWeave 強大的 H100 GPU 網路上進行訓練的。」
Inflection AI在2022年初由DeepMind的Mustafa和Karén Simonyan以及Reid Hoffman共同創立,盼透過與CoreWeave合作,使用NVIDIA的GPU建立全球最大的運算集群之一。
測試結果
測試結果這些使用者經驗反映了今天宣布的MLPerf基準測試中展示的性能。
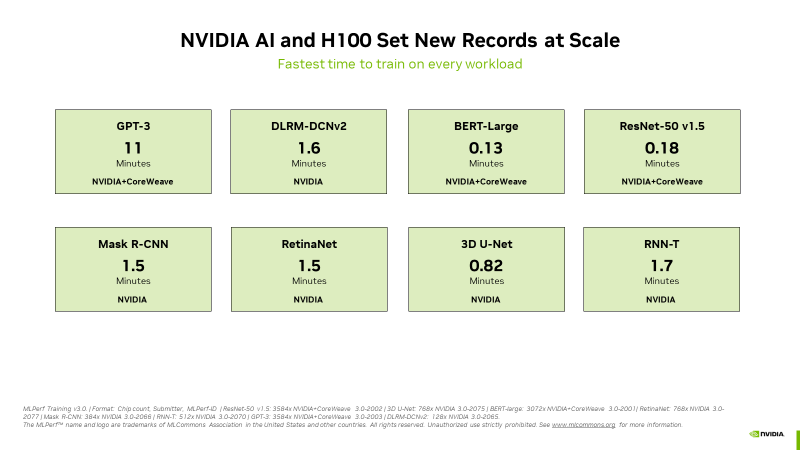
H100 GPU在每個基準測試中都提供了最高的效能,包括大型語言模型、推薦系統、電腦視覺、醫學影像和語音識別。它們是唯一可以執行所有八項測試的晶片,展示出 NVIDIA AI 平台的多功能性。
卓越的大規模執行能力
訓練通常是由多個GPU協同工作的大規模運行作業。在每個MLPerf測試中,H100 GPU在AI訓練方面創下了新的大規模效能紀錄。
本次提交的測試結果包括數百個到數千個H100 GPU,展現出整個技術堆疊的優化成果,並在嚴苛的LLM測試中實現了近線性的效能擴展。

此外,CoreWeave從雲端提供的性能與NVIDIA在本地資料中心運行的AI超級電腦實現的性能相似。這證明了CoreWeave所使用的NVIDIA Quantum-2 InfiniBand網路具備地低延遲網路性能。
在這一輪測試中,MLPerf還更新了用於推薦系統的基準測試。
新的測試使用了更大的資料集和更現代的AI模型,以更好地反映雲端服務供應商面臨的挑戰。NVIDIA是唯一一家在增強的基準測試上提交結果的公司。
不斷擴展的 NVIDIA AI 生態系統
本輪有近十幾家公司在NVIDIA平台上提交了結果。 他們的工作表明了 NVIDIA 人工智慧得到了業界最廣大的機器學習生態系的支持。
包括Microsoft Azure雲端服務、系統製造商華碩、戴爾科技集團、富士通、技嘉科技、Lenovo、雲達科技和美超微。超過30個是在H100 GPU上運行的成果。
這種程度的參與讓使用者知道,無論是在雲端還是在自身資料中心運行的伺服器,都可以透過NVIDIA 人工智慧獲得出色的效能。
跨越所有工作負載的效能
NVIDIA 生態系夥伴參與 MLPerf 是因為他們知道這對於客戶評估人工智慧平台和供應商來說是一個很有價值的工具。
這些基準測試涵蓋了用戶關心的工作負載——電腦視覺、翻譯和強化學習,以及生成式人工智慧和推薦系統。
使用者可以依靠 MLPerf 結果做出明智的購買決定,因為測試是透明且客觀的。 這些基準得到了包括 Arm、百度、Facebook AI、Google、哈佛大學、英特爾、微軟、史丹福大學和多倫多大學在內的廣泛支持。
現在H100、L4和NVIDIA Jetson平台上做的AI訓練、推論和高效能運算基準都有MLPerf的測試結果。NVIDIA也將在未來MLPerf中提交測試NVIDIA Grace Hopper系統的結果。
能源效率的重要性
隨著人工智慧效能的要求增長,提高實現效能的效率至關重要。 這就是加速運算的作用。
使用 NVIDIA GPU加速的資料中心使用更少的伺服器節點,因此使用更少的機架空間和能源。
此外,加速的網路可以提高效率和效能,而持續的軟體優化則能在相同的硬體上實現了更大的性能提升。
節能效能對環境和商業都非常有益。提升的效可以加快上市時間,讓組織能夠建立更先進的應用程式。節能效率也能降低成本,因為以NVIDIA GPU加速的資料中心使用更少的伺服器節點。
事實上,在最新 Green500 榜單上排名前 30 名的超級電腦中有22 套採用NVIDIA GPU。
人人都可使用的軟體
NVIDIA 人工智慧平台的軟體層NVIDIA AI Enterprise 可以使領先的加速運算基礎設達致優化的效能。 這個軟體配備了在企業資料中心運行人工智慧所需的企業級支持、安全性和可靠性。
於此次測試中使用的各種軟體公開於MLPerf資源庫,幾乎每個人都能取得這些世界級的成果。我們不斷將最佳化結果放入 NGC (NVIDIA的GPU 加速軟體目錄)的容器中。
敬請參閱我們的技術部落格,深入了解促使 NVIDIA MLPerf 效能與效率提升的最佳化技術。