
- 目前最智慧的前 10 大開源模型,均採用混合專家(MoE)架構。
- Kimi K2 Thinking、DeepSeek-R1、Mistral Large 3 等模型在 NVIDIA GB200 NVL72 上的運行速度可提升達 10 倍。

正如大腦會根據任務啟動特定區域,混合專家模型將工作分配給專門的「專家」,僅針對每個 AI 詞元啟動相關的專家。這使得詞元的產生速度更快、效率更高,而無需成比例地增加運算量。
業界已經認可這項優勢。在獨立的 Artificial Analysis(AA)排行榜上,排名前十的最智慧開源模型均採用混合專家架構,包括 DeepSeek AI 的 DeepSeek-R1、Moonshot AI 的 Kimi K2 Thinking、OpenAI 的 gpt-oss-120B,以及 Mistral AI 的 Mistral Large 3。
然而,在生產環境中擴展混合專家模型並保持高效能向來極具挑戰。NVIDIA GB200 NVL72 系統極致的協同設計,透過軟硬體的深度整合實現效能與效率的最大化,使混合專家模型的擴展變得實用且直覺。
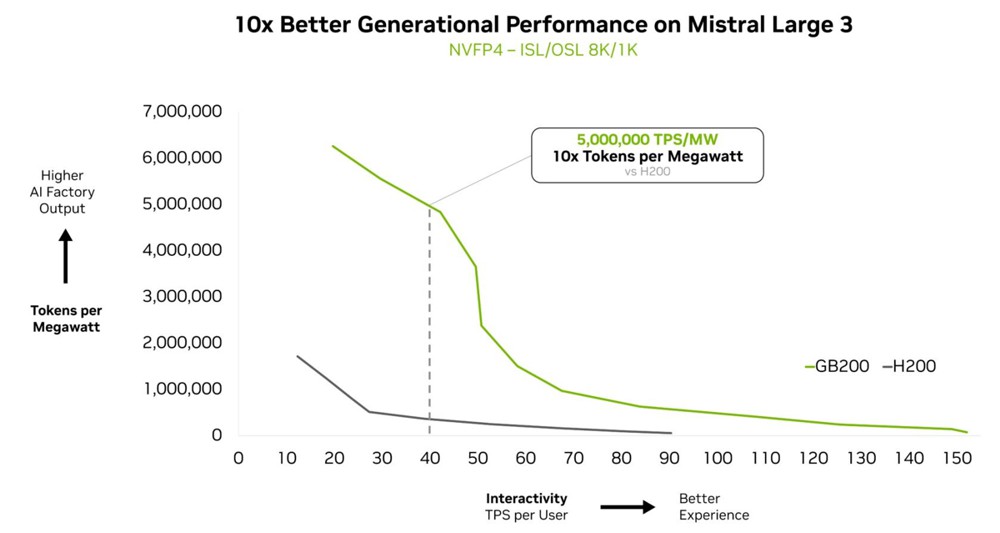
在 Artificial Analysis 排行榜上被評為最智慧的開源模型 Kimi K2 Thinking 混合專家模型,在 NVIDIA GB200 NVL72 機架級系統上的運算效能,較 NVIDIA HGX H200 提升10倍。這項突破性成果奠基於 DeepSeek-R1 與 Mistral Large 3 混合專家模型所展現的效能表現之上,彰顯混合專家正逐步成為前沿模型的首選架構,以及 NVIDIA 的全端推論平台是釋放其完整潛能的關鍵。
什麼是混合專家?為何混合專家已成為前沿模型的標準?
直至近期,業界打造更智慧 AI 的標準做法是建立更大、更密集的模型,這些模型會使用所有模型參數來產生每個詞元,而以當今最強大的模型而言,通常包含數千億個參數。雖然這樣的方法很強大,但需花費龐大的運算能力和能源,因此難以擴展。
就像人腦依靠特定區域來處理不同的認知任務一樣,無論是處理語言、識別物體還是解決數學問題,混合專家模型由多個專門的「專家」組成,對於任何給定的詞元,只有最相關的專家會被路由器啟動。這種設計意味著,即使整個模型可能包含數千億個參數,產生單一詞元時僅需使用其中的一小部分,通常是數百億個參數。
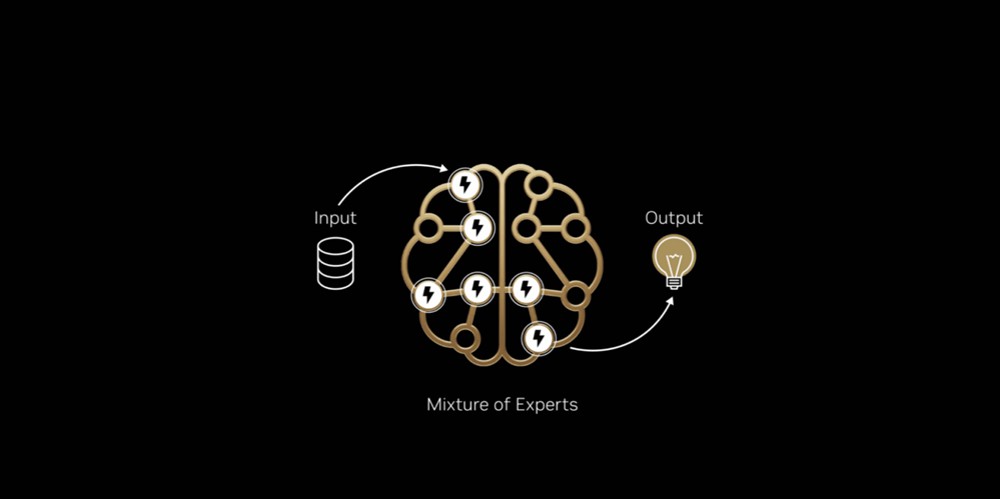
就像人類大腦會啟用負責不同任務的特定區域一樣,混合專家模型會透過路由器,只啟用最相關的專家來生成每一個詞元。
透過選擇性使用最重要的專家,混合專家架構能夠在不增加運算成本的狀況下,實現更高的智慧和適應性,使其成為高效 AI 系統的基礎,得以最佳化每元和每瓦特的效能表現,讓投入的每一單位能源和資本,都能創造出更多的智慧產出。
基於這些優勢,混合專家因此迅速成為前沿模型的首選架構,今年超過 60% 的開源 AI 模型版本都採用混合專家架構。自 2023 年初以來,該架構使模型智慧提升近 70 倍,推進AI 能力的極限。
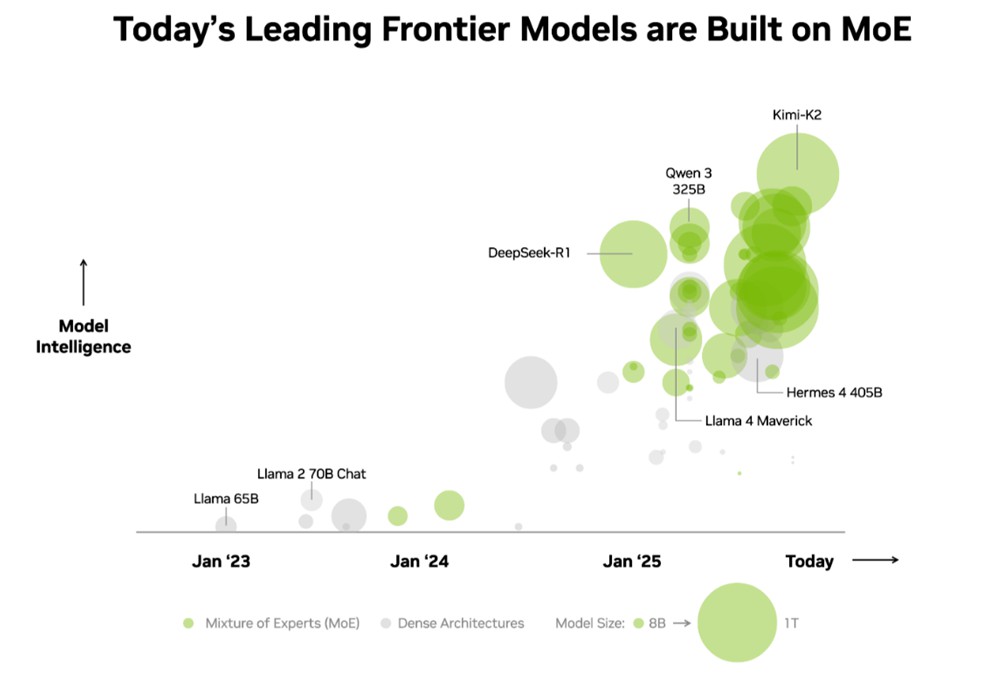
從2025年初起,幾乎所有的前沿模型都使用混合專家設計。
Mistral AI 共同創辦人暨首席科學家 Guillaume Lample 表示:「我們兩年前從 Mixtral 8x7B 開始,在開源軟體混合專家模型架構領域開展突破性成果,確保先進智慧技術能廣泛應用於各類場景,且兼具可用性與持續性。Mistral Large 3 的混合專家架構使我們能夠擴展 AI 系統,在大幅降低能耗和運算資源需求的同時,實現更高的效能和效率。」
透過極致協同設計克服混合專家的擴展瓶頸
最先進的混合專家模型,規模與複雜度都已遠遠超出單一 GPU 能力範圍。要讓這類模型順利運行,必須將眾多「專家」分散到多顆 GPU 上執行,也就是所謂的專家平行化(expert parallelism)。但即便是在 NVIDIA H200 這類強大平台上,部署混合專家模型時仍會遇到多種瓶頸,包括:
- 記憶體限制:每處理一個詞元,GPU 都必須從高頻寬記憶體(HBM)動態載入被選中的專家參數,導致記憶體頻寬承受頻繁且沈重的壓力。
- 延遲:各個專家必須執行近乎即時的全互連(all-to-all)通訊模式來交換資訊,才能匯聚成最終完整答案。然而在 H200 上,當專家分散到超過八顆 GPU 時,就必須透過較高延遲的橫向擴展網路來通訊,進而限制了專家平行化所能帶來的效益。
NVIDIA GB200 NVL72 為機架級系統,內含 72 顆 NVIDIA Blackwell GPU,以單一 GPU的形式協同運作,提供 1.4 exaflops 的 AI 效能與 30TB 的高速共享記憶體。這 72 顆 GPU 透過 NVLink Switch 串接成單一、龐大的 NVLink 互連網狀架構,讓每顆 GPU 間都能以每秒130 TB 的 NVLink 連線頻寬互相通訊。
混合專家模型可以善用這樣的設計,將專家平行化擴展到過去難以達成的境界,將專家分散到多達 72 顆 GPU 上。
這樣的架構設計,透過以下方式直接解決混合專家的擴展瓶頸:
- 降低每顆 GPU 上的專家數量:當專家被分散到最多 72 顆 GPU 上時,每顆 GPU 所承載的專家數量就能下降,進而降低各 GPU 高頻寬記憶體在載入參數時所承受的壓力。每顆 GPU 上的專家變少,也能釋放出更多記憶體空間,讓單一 GPU 能同步服務更多使用者,並支援更長的輸入長度。
- 加速專家通訊:分布在不同 GPU 上的專家可藉由 NVLink 即時互相通訊。NVLink Switch 本身也具備足夠的運算能力,能處理部分整合多個專家資訊所需的計算,進一步加快輸出最終答案的速度。

其他全端最佳化同樣是釋放混合專家推論效能的關鍵。NVIDIA Dynamo 框架負責協調解耦式服務(disaggregated serving),將預填(prefill)與解碼(decode)任務分派到不同 GPU 上,讓解碼能搭配大規模專家平行化運行,而預填則採用更適合其工作負載的平行化技術。NVFP4 格式可在維持準確度的同時,進一步提升效能與能源效率。
NVIDIA TensorRT-LLM、SGLang 與 vLLM 等開源推論框架,都已支援這些混合專家模型最佳化。其中,SGLang 對於推進 GB200 NVL72 上的大規模混合專家發揮了顯著作用,協助驗證並完善今日廣泛採用的多項技術。
為了將這樣的效能帶給全球企業,GB200 NVL72 正由多家大型雲端服務供應商與 NVIDIA 雲端合作夥伴導入,包括 Amazon Web Services、Core42、CoreWeave、Crusoe、Google Cloud、Lambda、Microsoft Azure、Nebius、Nscale、Oracle Cloud Infrastructure、Together AI 等。
CoreWeave 共同創辦人暨技術長 Peter Salanki 表示:「在 CoreWeave,客戶正運用我們的平台,將混合專家模型導入生產環境,打造各式代理型工作流程。透過與 NVIDIA 的緊密合作,我們得以提供一個高度整合的平台,將混合專家效能、擴展性與可靠性集於一身。只有在專為 AI 而生的雲端環境中,才能做到這一點。」
DeepL 等客戶也正運用 Blackwell NVL72 機架級設計來建構並部署下一代 AI 模型。
DeepL 研究團隊主管 Paul Busch 表示:「DeepL 正使用 NVIDIA GB200 硬體來訓練混合專家模型,藉此在訓練與推論階段提升模型架構效率,在 AI 效能上樹立全新標竿。」
以每瓦效能展現實力
NVIDIA GB200 NVL72 能以高效擴展複雜的混合專家模型,在每瓦效能上實現 10 倍躍進。這不只是基準測試上的表現,而是能為即時、大規模 AI 工作負載帶來 10 倍的詞元產出效益,徹底改變受限於能源與成本的資料中心,在大規模AI部署下的經濟模式。
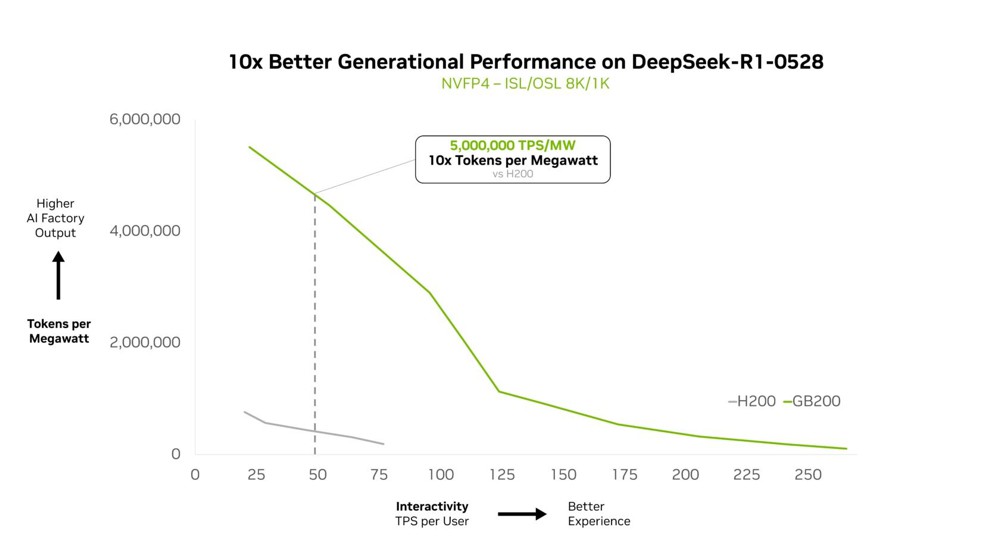
在 NVIDIA GTC Washington, D.C. 大會上,NVIDIA 創辦人暨執行長黃仁勳特別說明了 GB200 NVL72 如何在 DeepSeek-R1 模型上提供相較 NVIDIA Hopper 高出 10 倍的效能,而這樣的效能優勢同樣延伸到其它 DeepSeek 版本。
Together AI 共同創辦人暨執行長 Vipul Ved Prakash 表示:「結合 GB200 NVL72 與 Together AI 的客製最佳化,我們在像 DeepSeek-V3 這樣的大規模混合專家推論工作負載上,已能超越客戶預期。這些效能成長源自 NVIDIA 全端最佳化,再加上 Together AI Inference 在核心函式庫、執行階段引擎與推測解碼(speculative decoding)上的突破。」
這項效能領先優勢,同樣反映在其他前沿模型上。
被視為最智慧的開源模型之一的 Kimi K2 Thinking,則為另一個證明:在 GB200 NVL72 上部署時,其生成效能提升達 10 倍。
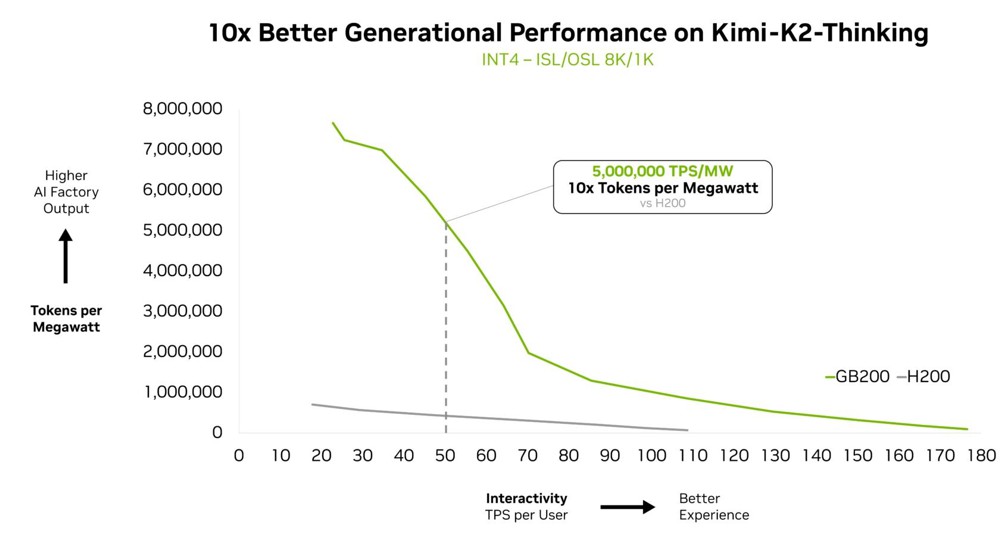
Fireworks AI 目前已在 NVIDIA B200 平台部署 Kimi K2,以在 Artificial Analysis 排行榜取得頂尖表現。
Fireworks AI 共同創辦人暨執行長 Lin Qiao 表示:「NVIDIA GB200 NVL72 機架級設計,讓混合專家模型服務的效率大幅提升。展望未來,NVL72 有潛力徹底改變我們服務超大規模混合專家模型的方式,相較 Hopper 平台帶來顯著的效能改善,為前沿模型的速度與效率樹立全新標竿。」
Mistral Large 3 在 GB200 NVL72 上,也較前一代 H200 平台實現了 10 倍的效能成長。這樣世代間的躍進,轉化為更佳的使用者體驗、更低的單詞元成本,以及更高的能源效率。
驅動大規模智慧
NVIDIA GB200 NVL72 機架級系統的設計,目標是在混合專家模型之外,同樣提供強大的 AI 效能。
觀察 AI 發展的方向即可理解原因:最新一代多模態 AI 模型通常包含專門處理語言、視覺、音訊與其他模態的組件,並只在當下任務需要時啟用相關組件。
在代理型系統中,不同「代理」則分別專精於規劃、感知、推理、工具使用或搜尋等工作,再由一個協調者整合它們的輸出,形成單一結果。這兩種情境的核心模式都與混合專家類似:將問題的各個部分導向最適合的專家,最後再協調並整合其輸出,產出最終結果。
當這個概念擴展到實際生產環境中,由多個應用與代理共同服務多位使用者時,就能解鎖全新的效率層級。與其為每個代理或應用分別複製一整套龐大 AI 模型,此方式能建立開放存取的共用專家池,將每一個請求導向最合適的專家。
混合專家是一種強大的架構,正推動產業邁向一個能力強大、效率與規模得以並存的未來。GB200 NVL72 今日已將這項潛力化為現實,而搭載 NVIDIA Vera Rubin 架構的未來產品藍圖,將持續拓展前沿模型的邊界。
想更深入了解 GB200 NVL72 如何擴展複雜混合專家模型,可參閱此篇技術深度解析。