AMD Instinct MI200系列加速器採用全新AMD CDNA™ 2架構,與對手的資料中心加速器相比,在HPC效能方面提供極具突破性的4.9倍提升註1,加速科學研發
AMD Instinct MI200系列加速器為首款多晶片(multi-die)GPU,率先支援128GB的HBM2e記憶體,為科學基礎的關鍵應用提供大幅效能提升
AMD Instinct MI200系列加速器為首款多晶片(multi-die)GPU,率先支援128GB的HBM2e記憶體,為科學基礎的關鍵應用提供大幅效能提升
AMD(NASDAQ: AMD)今日發表全新AMD Instinct™ MI200系列加速器,為首款exascale等級的GPU加速器。AMD Instinct MI200系列加速器中的AMD Instinct™ MI250X為全球最快的高效能運算(HPC)與人工智慧(AI)加速器註1。

AMD Instinct MI200系列加速器基於AMD CDNA™ 2架構打造,可為廣泛的HPC工作負載提供領先的應用效能註2。在雙精度(FP64)HPC應用中,AMD Instinct MI250X加速器提供比競爭對手加速器高達4.9倍的效能提升,並為AI工作負載提供超過380 teraflops的半精度(FP16)尖峰理論效能,以強大的效能進一步加速資料導向的研究註1。
AMD全球資深副總裁暨資料中心與嵌入式解決方案事業群總經理Forrest Norrod表示,AMD Instinct MI200加速器提供了領先的HPC與AI效能,協助科學家在研究工作中實現跨世代的進展,大幅縮短從最初假設到實際印證的時間。憑藉在架構、封裝以及系統設計方面的關鍵性創新,AMD Instinct MI200系列加速器為有史以來最先進的資料中心GPU,為超級電腦與資料中心挹注卓越效能,以解決全球最複雜的難題。
AMD引領Exascale時代
AMD與美國能源部、橡樹嶺國家實驗室以及HPE聯手設計Frontier超級電腦,預計可提供超過1.5 exaflops的尖峰運算效能。搭載優化的AMD第3代EPYC™ CPU與AMD Instinct MI250X加速器,Frontier將透過大幅提升的AI、分析、大規模模擬效能,推動科學探索的發展,協助科學家完成更多計算、從資料洞悉出新模式,並開發創新的資料分析方法,從而加快科學發現的步伐。
橡樹嶺國家實驗室總監Thomas Zacharia表示,Frontier超級電腦是AMD、HPE以及美國能源部緊密合作的結晶,旨在提供具有exascale等級運算能力的系統,透過大幅提升人工智慧、分析、大規模模擬的效能,推動科學探索的發展。
推動HPC的未來發展
AMD Instinct MI200系列加速器搭配AMD第3代EPYC CPU與ROCm™ 5.0開放軟體平台,旨在推動exascale等級時代的新發現,並解決從氣候變遷到疫苗研究等最迫切的挑戰。
AMD Instinct MI200系列加速器的關鍵功能與特色包括:
AMD CDNA™ 2架構-第2代Matrix Cores加速的FP64與FP32矩陣運算,帶來比AMD前一代GPU高達4倍的FP64尖峰理論效能提升註1,3,4。
領先的封裝技術-業界首款採用多晶片(multi-die)GPU設計與2.5D Elevated Fanout Bridge技術(EFB),與AMD前一代GPU相比,可提供1.8倍的核心數以及2.7倍的記憶體頻寬,帶來業界最佳的聚合尖峰理論記憶體頻寬,每秒達到3.2 terabytes註4,5,6。
AMD第3代Infinity Fabric™技術-多達8個Infinity Fabric通道將AMD Instinct MI200與節點中的第3代EPYC CPU和其他GPU連結,實現統一CPU/GPU記憶體的一致性,達到最高的系統吞吐量,藉由加速器的強大效能讓CPU程式碼更簡化。
專為Exascale等級科學研發打造的軟體
AMD ROCm™為開放軟體平台,讓研究人員能發揮AMD Instinct™加速器的強大效能,推動科學探索。ROCm平台基於開放可攜性的基礎,支援各加速器供應商與各種架構環境。AMD藉由ROCm 5.0拓展其開放平台,透過AMD Instinct MI200系列加速器支援頂尖HPC與AI應用,為開發者增進ROCm的可及性,並在關鍵工作負載中提供卓越效能。
藉由AMD Infinity Hub,研究人員、資料科學家和終端使用者可以輕鬆地搜尋、下載並安裝在AMD Instinct加速器和ROCm上優化和支援的容器化HPC應用與機器學習(ML)框架。AMD Infinity Hub目前提供眾多容器,支援Radeon Instinct™ MI50、AMD Instinct™ MI100與AMD Instinct MI200加速器,Chroma、CP2k、LAMMPS、NAMD、OpenMM等多種應用,以及TensorFlow和PyTorch等熱門ML框架。AMD Infinity Hub也持續在增加新容器。
現有的伺服器解決方案
AMD Instinct MI250X和AMD Instinct MI250目前以開放硬體運算加速器模組或OCP加速器模組(OAM)的規格供貨。AMD Instinct MI210將以PCIe®介面卡規格搭載於OEM伺服器。
AMD Instinct MI250X加速器目前搭載於HPE的HPE Cray EX超級電腦,更多AMD Instinct MI200系列加速器預計將從2022年第1季開始搭載於各大OEM與ODM夥伴廠商的企業系統,包括華碩、ATOS、戴爾科技集團、技嘉、HPE、聯想、Penguin Computing以及美超微(Supermicro)。
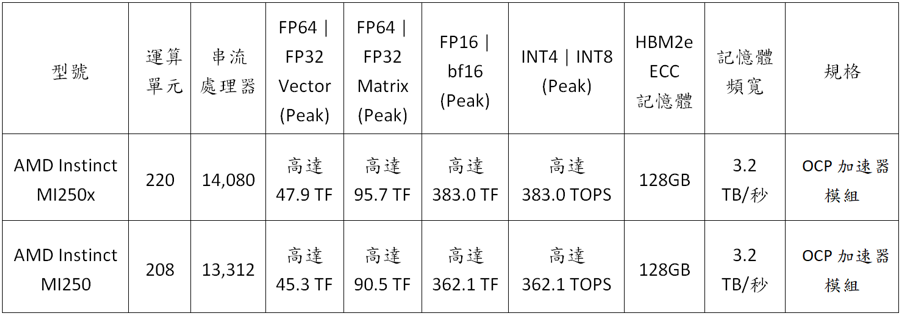
AMD MI200系列規格
註1:全球最快資料中心GPU是AMD Instinct™ MI250X。計算是由AMD實驗室於2021年9月15日執行,受測的AMD Instinct™ MI250X(128GB HBM2e OAM模組)加速器在1,700 MHz尖峰升頻引擎時脈下測得95.7 TFLOPS尖峰理論倍精度(FP64 Matrix)、47.9 TFLOPS 尖峰理論倍精度(FP64)、95.7 TFLOPS尖峰理論單精度矩陣(FP32 Matrix)、47.9 TFLOPS尖峰理論單精度(FP32)、383.0 TFLOPS尖峰理論半精度(FP16)以及383.0 TFLOPS尖峰理論Bfloat16格式精準度(BF16)浮點運算效能。計算是由AMD效能實驗室於2020年9月18日執行,受測對象為AMD Instinct™ MI100(32GB HBM2 PCIe®介面卡)加速器,1,502 MHz尖峰升壓引擎時脈下測得11.54 TFLOPS尖峰理論倍精度(FP64)、46.1 TFLOPS尖峰理論單精度矩陣(FP32)、23.1 TFLOPS尖峰理論單精度(FP32)、184.6 TFLOPS尖峰理論半精度(FP16)浮點運算效能。公布結果反映NVIDIA Ampere A100 (80GB) GPU加速器在升壓引擎時脈1410 MHz下測得19.5 TFLOPS尖峰倍精度tensor核心(FP64 Tensor Core)、9.7 TFLOPS尖峰倍精度(FP64)、19.5 TFLOPS尖峰單精度(FP32)、78 TFLOPS 尖峰半精度(FP16)、312 TFLOPS尖峰半精度(FP16 Tensor Flow)、39 TFLOPS 尖峰Bfloat 16 (BF16)、312 TFLOPS尖峰Bfloat16格式精度(BF16 Tensor Flow)的理論浮點運算效能。TF32資料格式不是IEEE協會的相容規格,這項比較沒有採用。https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf, 第15頁表格1。
註2:AMD Instinct MI250X加速器應用與量測效能的詳細資訊可參閱https://www.amd.com/en/graphics/server-accelerators-benchmarks。
註3:計算由AMD效能實驗室於2021年9月15日執行,受測對象為AMD Instinct™ MI250X 加速器(128GB HBM2e OAM模組),1,700 MHz 尖峰升壓引擎時脈,測得95.7 TFLOPS尖峰倍精度矩陣(FP64 Matrix)理論浮點運算效能。公布結果NVIDIA Ampere A100 (80GB) GPU 加速器測得19.5 TFLOPS 尖峰倍精度(FP64 Tensor Core)理論浮點運算效能。上述結果參照官網文件:https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf,第15頁表格1。
註4:計算由AMD效能實驗室於2021年9月21日執行,受測對象為AMD Instinct™ MI250X 與MI250 (128GB HBM2e) OAM加速器,採用AMD CDNA™ 2、6奈米FiNFET製程技術進行研發,1,600 MHz尖峰記憶體時脈,配備128GB HBM2e 記憶體容量,3.2768 TFLOPS尖峰理論記憶體頻寬效能。MI250/MI250X記憶體匯流排介面4,096 bits 乘以2個晶片以及記憶體資料傳輸率3.20 Gbps,推算出總記憶體頻寬為3.2768 TB/s ((3.20 Gbps*(4,096 bits*2))/8)。公布的最高量測數據是在NVIDIA Ampere A100 (80GB) SXM GPU加速器上測得,80GB HBM2e記憶體容量,測得2.039 TB/s GPU記憶體頻寬效能。 https://www.nvidia.com/content/dam/…a-a100-datasheet-us-nvidia-1758950-r4-web.pdf。MI200-07
註5:AMD Instinct™ MI250X加速器內含220個運算單元(CU)與14,080 個串流核心。AMD Instinct™ MI100加速器內含120 個運算單元(CU)與7,680個串流核心。
註6:計算是由AMD效能實驗室於2021年9月21日執行,受測對象為AMD Instinct™ MI250X與MI250 (128GB HBM2e) OAM加速器,晶片採用AMD CDNA™ 2、6奈米FinFet製程技術,1,600 MHz尖峰記憶體時脈,測得3.2768 TFLOPS尖峰理論記憶體頻寬效能。MI250/MI250X記憶體匯流排介面的4,096 bits乘以2個晶片與記憶體資料傳輸率3.20 Gbps,推算出總記憶體頻寬為3.2768 TB/s ((3.20 Gbps*(4,096 bits*2))/8)。計算由AMD效能實驗室於2020年10月5日執行,受測對象為AMD Instinct™ MI100加速器,晶片採用AMD CDNA 7奈米FinFET製程技術,1,200 MHz尖峰記憶體時脈,測得1.2288 TFLOPS尖峰理論記憶體頻寬效能。MI100記憶體匯流排介面為4,096 bits,記憶體資料傳輸率為2.40 Gbps,故推算出總記憶體頻寬為1.2288 TB/s ((2.40 Gbps*4,096 bits)/8)。