
NVIDIA 昨晚在 GTC 2017 大會上正式發布了 Volta,不過可想而知是旗艦計算卡,而非桌上型顯卡,型號是 Tesla V100。

對比上一代 Tesla P100,Tesla V100 最大變化就是增加了與深度學習高度相關的 Tensor單元,Tensor 性能可以達到120 TFLOPS;而且 CUDA 數目暴增,由3584個增至5120個,增長了42%;全新的台積電12nm FFN製程製造有史以來最大的815mm2 GPU核心(16nm的第四代改良版本,更高的晶體管密度,更低的功耗;可能 Volta 顯卡都是使用這個製程);雖然依然是4096bit 16GB的HBM2記憶體,但是帶寬從原本 Tesla P100 的720GB/s提升至900GB/s。

除了 CUDA 單元數量增加,Tesla V100 為了更好提升高效能計算,繼續增加二級快取及寄存器大小,L2快取由 Tesla P100 的4096KB增加到了6144KB,每組SM單元的寄存器文件大小總數從14336KB增加到了20480KB 。
NVIDIA 計算卡專享的 NVLink 是一種高頻寬的互聯技術,能夠在 CPU-GPU 和 GPU-GPU 之間實現超高速的數據傳輸,可以有 PCIe 3.0 5-12倍的數據傳輸速度,還能大幅提升應用程序的處理速度。現在 NVIDIA 將其提升至300GB/s水平,當然了這個技術主要還是用在高效能計算上,估計不會下放至遊戲用的顯卡上。
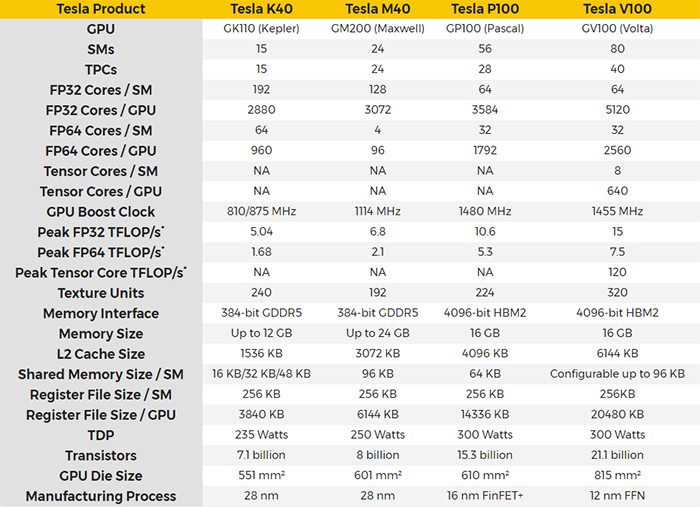
Tesla V100架構:
6組GPC單元,每組 GPC 單元由14組 SM 單元構成,滿血版應該是6 x 14 = 84組 SM 單元,但 Tesla V100 只有80組,每組 SM 單元64個 CUDA 單元,因此共同構成80 x 64 = 5120個 CUDA 單元。每組 SM 單元中,FP32:FP64:Tensor 單元比例為8:4:1。

NVIDIA Tesla V100 將會率先更新用於深度學習超算 DGX-1 上,內部同樣集成了8張 Tesla V100,提供960 TFLOPS Tensor深度計算效能,能夠在8小時完成 TITAN X 需時8天的計算量,極大地節約科研人員等待深度計算結果時間。當然這要價並不便宜,擁有8張的新 DGX-1 售價為149000美元,約台幣451萬。

來源:http://www.expreview.com/54059.html
對比上一代 Tesla P100,Tesla V100 最大變化就是增加了與深度學習高度相關的 Tensor單元,Tensor 性能可以達到120 TFLOPS;而且 CUDA 數目暴增,由3584個增至5120個,增長了42%;全新的台積電12nm FFN製程製造有史以來最大的815mm2 GPU核心(16nm的第四代改良版本,更高的晶體管密度,更低的功耗;可能 Volta 顯卡都是使用這個製程);雖然依然是4096bit 16GB的HBM2記憶體,但是帶寬從原本 Tesla P100 的720GB/s提升至900GB/s。
除了 CUDA 單元數量增加,Tesla V100 為了更好提升高效能計算,繼續增加二級快取及寄存器大小,L2快取由 Tesla P100 的4096KB增加到了6144KB,每組SM單元的寄存器文件大小總數從14336KB增加到了20480KB 。
NVIDIA 計算卡專享的 NVLink 是一種高頻寬的互聯技術,能夠在 CPU-GPU 和 GPU-GPU 之間實現超高速的數據傳輸,可以有 PCIe 3.0 5-12倍的數據傳輸速度,還能大幅提升應用程序的處理速度。現在 NVIDIA 將其提升至300GB/s水平,當然了這個技術主要還是用在高效能計算上,估計不會下放至遊戲用的顯卡上。
Tesla V100架構:
6組GPC單元,每組 GPC 單元由14組 SM 單元構成,滿血版應該是6 x 14 = 84組 SM 單元,但 Tesla V100 只有80組,每組 SM 單元64個 CUDA 單元,因此共同構成80 x 64 = 5120個 CUDA 單元。每組 SM 單元中,FP32:FP64:Tensor 單元比例為8:4:1。
NVIDIA Tesla V100 將會率先更新用於深度學習超算 DGX-1 上,內部同樣集成了8張 Tesla V100,提供960 TFLOPS Tensor深度計算效能,能夠在8小時完成 TITAN X 需時8天的計算量,極大地節約科研人員等待深度計算結果時間。當然這要價並不便宜,擁有8張的新 DGX-1 售價為149000美元,約台幣451萬。
來源:http://www.expreview.com/54059.html