
國外 Chips and Cheese 網站針對 AMD 以及 NVIDIA 顯卡 GPU 延遲進行了測試,AMD 標榜新卡 RDNA2 所配置的 Infinity Cache 似乎有帶來更好的優勢。

該網站表示測試基準是採用 OpenCL 編寫,用於測試 GPU 記憶體快取中的延遲,RDNA 2 高速快取有相當的優勢。與 Ampere 相比,快取延遲要低得多,而 VRAM 延遲則大致相同。NVIDIA 使用由 L1 和 L2 組成的兩級快取系統,這似乎是一個相當慢的解決方案。從擁有 L1 快取的 Ampere SM 傳輸到外部 L2 的數據需要 100ns 的延遲。
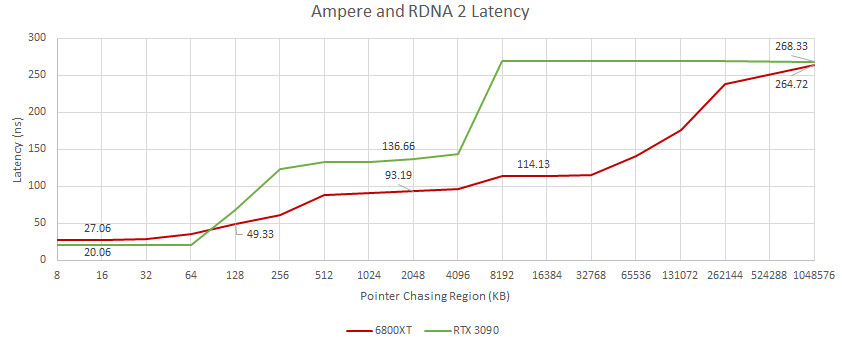
另一方面 AMD RDNA2 架構具有 L0、L1 以及 L2 快取,L1 到 L2 之間僅有 66ns,Infinity Cache 本質上是 L3 快取,僅增加了 20ns 的額外延遲,與 NVIDIA 的快取解決方案相比,顯而立見。NVIDIA 的 GA102 較高的延遲似乎是 L2 快取無法解決的一個大問題,因此需要花費較多時間。
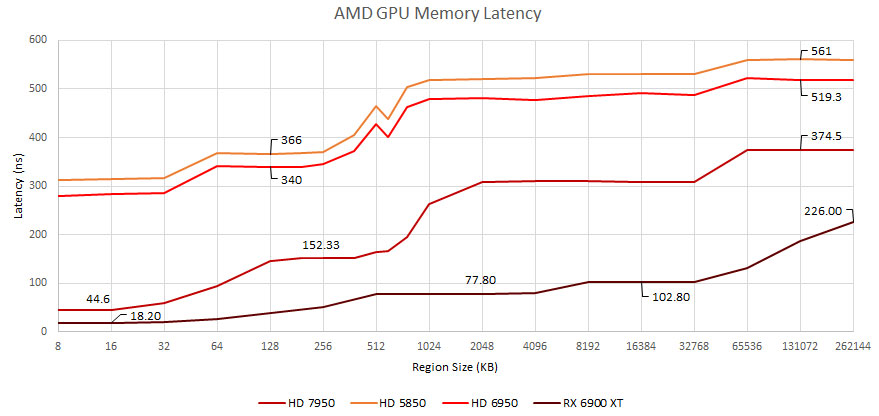
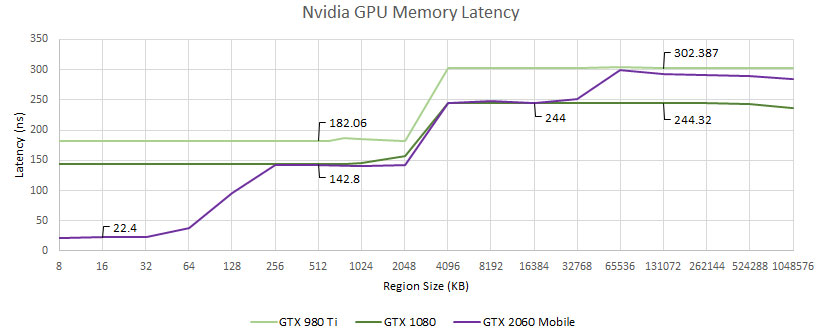
另外測試也針對了新舊卡的延遲進行比較,可以看到 AMD 與 NVIDIA 在延遲上都有一些改善。
來源
該網站表示測試基準是採用 OpenCL 編寫,用於測試 GPU 記憶體快取中的延遲,RDNA 2 高速快取有相當的優勢。與 Ampere 相比,快取延遲要低得多,而 VRAM 延遲則大致相同。NVIDIA 使用由 L1 和 L2 組成的兩級快取系統,這似乎是一個相當慢的解決方案。從擁有 L1 快取的 Ampere SM 傳輸到外部 L2 的數據需要 100ns 的延遲。
另一方面 AMD RDNA2 架構具有 L0、L1 以及 L2 快取,L1 到 L2 之間僅有 66ns,Infinity Cache 本質上是 L3 快取,僅增加了 20ns 的額外延遲,與 NVIDIA 的快取解決方案相比,顯而立見。NVIDIA 的 GA102 較高的延遲似乎是 L2 快取無法解決的一個大問題,因此需要花費較多時間。
另外測試也針對了新舊卡的延遲進行比較,可以看到 AMD 與 NVIDIA 在延遲上都有一些改善。
來源